A (not so) brief summary of spaCy IRL, 2019

We first heard of spaCy back in 2015, somewhere around their first release (back in 2015), and have been using it ever since pretty much for every project. Naturally, when we heard about spaCy IRL, we were pretty excited and decided to attend the conference (meetup?).
What follows is a summary of the event, held on July 6th in Neuköln, Berlin. Briefly, the event comprised of a compendium of fascinating talks from academicians sharing research ideas, discussing their works, as well as industry leaders discussing the ways NLP helps them, and the insights they gained from working on a myriad applied NLP projects. As we see it, spaCy IRL went a long way in bridging the gap between academia and industry. potato
This blog was written in collaboration with a colleague who attended the event alongwith. The content is available on his site as well.
Transfer Learning in Open Source NLP - Sebastian Ruder
twitter | site
The event started with a keynote from Sebastian Ruder, where he talked about Transfer Learning in NLP, and the role of open source community/platforms/softwares driving the field forward. Sebastian motivated his talk by this very interesting example (Fig. below), charting the progress of state-of-the-art approaches on the NER CoNLL-2003 (English) task where the spike towards 2016-2019 was driven by advances in transfer learning techniques in the field.
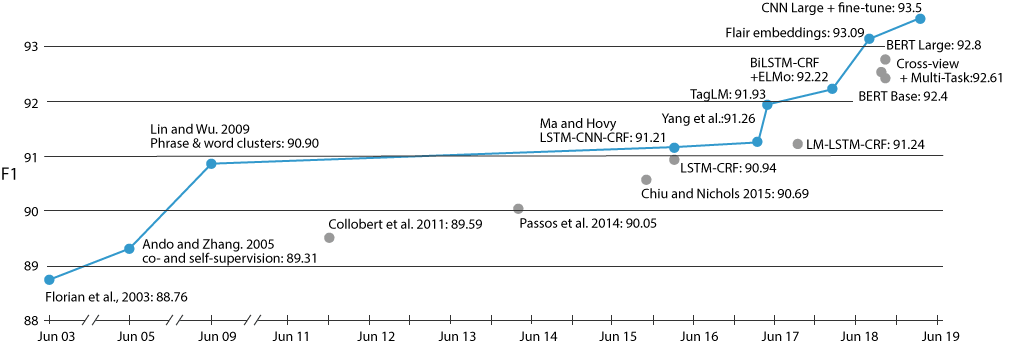
A majority of this progress is driven by the use of largescale pretrained language models (Radford, Narasimhan, Salimans, & Sutskever, 2018; Devlin, Chang, Lee, & Toutanova, 2019; Peters et al., 2018; Howard & Ruder, 2018) for the task - a development which extends far beyond the task above. Sebastian provided an excellent overview of the field, covering the fundamental whens, hows, and whys1.
The second part of his talk focused on open-science practices in NLP research & development including sharing data, code, and trained models. He emphasized the need for sharing (as well as using shared) pre-trained models, and the different ways this is done today. This includes hubs such as Tensorflow Hub, Pytorch Hub, third party libraries like HuggingFace , and author-released model checkpoints. He then sheds light/discusses the open source practices highlighting various tool kits, models released by Deepmind, where he currently works.
The most interesting part of this talk, in our opinion, was his comments on the current shortcomings and future directions of this field. Some of the points he raised (and immaculately phrased, of course) included the incompatible nature/inability of the language model objective (predicting the next word, given context) to model Right-to-Left (RTL) scripts, and downstream tasks which require bidirectional information flow (Dong et al., 2019); weak signal for a semantic understanding of language; and the inability to handle scenarios/need for retraining where the downstream tasks involve multiple inputs2. He then shed some light on the recent advances in specialized pretraining tasks - (Joshi, Choi, Levy, Weld, & Zettlemoyer, 2018; Swayamdipta et al., 2018; Kiela, Wang, & Cho, 2018), and concluded the discussion with potential improvements in mechanisms of integrating pretrained models into development workflows, further democratizing largescale models.
You can find the slides for a similar talk at a tutorial at NAACL 2019, co-organized by Sebastian here.
“So when will spaCy support BERT?” Improving sparse transformer models for efficient self-attention - Giannis Daras
Closely related to the above talk, Giannis discussed his yet unpublished work on decreasing the space/computational complexity of transformers by further improving the sparse attention mechanism, originally proposed in (Child, Gray, Radford, & Sutskever, 2019). In a nutshell, these transformers avoid the n n computations, by factorizing the attention matrix, bringing the $O(n^2)$ complexity down to upto $O(n\sqrt{n})$, where each output position only computes weightings from a subset of input positions. Giannis’s work proposes different factorizations, along with their bidirectional variations, and demonstrates promising results on NLP tasks. This work further propagates the use of large transformer based models in low-compute scenarios, as sparse attention uses significantly less memory and computations. Imagine training BERT on a GTX1080, with a batch size of more than 10 !🎉🎉🎉
You can find the slides of this talk here.
Applied NLP: Lessons from the Field - Peter Baumgartner
twitter | site
Peter Baumgartner from RTI International delivered an absolutely hilarious, and artfully crafted talk, focused on relationships between NLP Research/Devs & Clients. He brilliantly utilized quirky illustrations, and relatable images (e.g. see below) to get the message across, which was composed of numerous insights he’s picked up while doing NLP in the wild. Personally, both Gaurav and I are driven by his suggestion of starting a blog, where he referenced this excellent post by Rachel Thomas.

I’m planning to print posters/stickers outta this.
Peter has written an excellent blog post about the same, here.
Lessons learned in helping developers ship conversational AI assistants to production - Justina Petraitytė
twitter | site
In her talk, Justina discusses the relationship of RASA with the open source community, and shared valuable insights regarding the design of such conversational AI platform. Rasa is a conversation AI platform/a platform to make chatbots. She explains the inherent difficulty in natural language understanding, focusing on challenges specific to NLU in conversational scenarios. These explanations are motivated by examples, such as - “I’d go hungry before I eat sushi” reg. negation, or the structural similarity between “can you help me log into my account?”, and “can i give someone else access to login to my account?”. She talks about the challenges faced when these agents are deployed in the wild. From handling typos, netspeak, to downright out of scope utterances like trying to order pizza from a navigational chatbot, she covers a wide spectrum of potential pitfalls. Justina emphasizes on the need of fall back mechanism and failing gracefully, in providing a cohesive experience to end-users. Given their myriad use cases, Justina says that, as developers of conversational AI platforms, we are not omniscient and must rely on the community around the product to fill in the gaps, and let other developers tailor the platform to their specific needs. The need to open sourcing Rasa (and other such platforms) is important, and doing so has been pivotal in making Rasa successful. And successful, it sure has been - having 300+ contributors, 5500+ community members, and 500k+ downloads. This talk felt very close to our experience as dialogue engineers, and we’ve personally felt some of the insights she shared.as dialogue engineers, and we’ve personally felt some of the insights she shared.
You can listen to her talk (and fawn over those beautifully crafted slides) here.
The missing elements in NLP - Yoav Goldberg
twitter | site
After the lunch break or a “social session”, Yoav Golberg presents his view on important open challenges in NLP research. He charts the trends in academic NLP over the decades; from rule based (50s-90s) to deep learning systems (2014-current). Through this, he sets desirable targets for the next shift in the field, where we’d ideally want approaches with little data requirements, transparent debuggability, little linguistic expertise.

He emphasizes the gap between academic NLP and its application in industrial setting , stating that the latter still, by and large, uses pattern matching and simple statistical approaches like tf-idf, topic modeling, svms, and most importantly regular expressions!
“Deep Learning is not enough” - Yoav Goldberg
“Deep learning is not enough,” says Yoav, given that it is slow, bad with nuances, contains biases and is hard to control. BERT, ELMo are surprisingly well, except when they’re not. When they fail, they fail in a very very stupid manner. Along these lines, Yoav motivates the need to bridge symbolic and deep learning based approaches, and discusses some of the gaps in modern NLP research:
-
- Injecting domain knowledge to plug the gaps in NN models.
- Syntax patterns are powerful, efficient, and transparent when working in specific domains. Mechanisms to integrate these patterns along with neural models for reliably performing NLP tasks can be of great benefit to the community and can work with very little training data.
-
- Representations that non-technical users can interpret and play with.
- For instance, the use of POS tags in industry is common. Meanwhile, syntax tree based representations which are much more informative are far uncommon. He attributes this partly to the expertise required to interpret them.
-
- Handling different linguistic phenomena.
- Complex linguistic phenomenons such as bridging, dystmesis, or numerical fused heads can be handled in a neural setting by actively isolating and attacking them (Elazar & Goldberg, 2019).
-
- Better model development workflows.
- Currently, a deep learning model development goes like this: you instantiate some model, train it, tune it and that’s that. It works sufficiently well, or it doesn’t. And if not, you start from scratch. Yoav calls for a process where solutions should be developed in active collaboration between human reasoning, and machine computations.
Personally, we’ve run into these issues countless times. We’ve had our development workflows full of throwing arbitrary architectures at a dataset, to see what sticks. We’ve seen scenarios (or syntactic structures) where our model runs into the ground, head first. And we’ve wanted to plug these leaks in a seamless manner. Yoav brought up some excellent, relatable point in his talk, and this summary surely doesn’t do it justice. You can find a video recording of his talk here.
Entity linking functionality in spaCy: grounding textual mentions to knowledge base concepts - Sofie Van Landeghem
Sofie talked about adding an entity-linking component in spaCy. At its core, entity linking is the task of finding and linking all the entities mentioned in text to an underlying KG (DBpedia, WikiData). She motivates the difficulty of the problem by a bunch of examples, amongst them we found the one below really interesting: “This happened to Delorean owner John Carson shortly after he was presented with the vehicle.” Here, “John Carson” can refer to either American talk show host or the footballer, and there is no way to disambiguate them without background knowledge. Apart from the inherent difficulty of the task, she also points out that an important consideration while designing a module for spaCy is the space and time complexity. With this in mind, she proposes latent encoding of NER spans, and corresponding entity candidates, as the features over which a classifier is trained to predict $P(E/Mention)$. The feature representations corresponding to each of the million WikiData entities are stored in-memory, in mere ~350MB, which is downright astonishing, in our opinion 🤯.
For more details about the evaluation and the approach, check out her slides here.
Rethinking rule-based lemmatization - Guadalupe Romero
Guadalupe talks about her experience, improving the lemmatization module for Spanish and German in spaCy. A good lemmatizer according to her is one, which can handle OOV words, with a reasonably good accuracy and efficiency, when working on morphologically rich languages. Current implementations of lemmatizations, based on lookup tables falls short of this, given that lookup tables aren’t (and probably cannot be) exhaustive, and do not handle out of vocabulary instances. Neural approaches, which she experiments with, provide promising results but were slow, specially for a component as fundamental as lemmatizer. Instead, she explored the use of rule-based systems for the task. The first challenge here is the fact that morphological dependencies (verb based for Spanish, noun & verb based for German) lead to a very large set (1000+) of such rules for a reasonably accurate lemmatizer. Choosing a rule can thus lead to ambiguous rule applications (based solely on the system’s priors), which is indeed undesirable. She thus proposes grouping rules based on these morphological dependencies or features, and include them in the rule selection process. In doing so, the system outputs ambiguous lemmas only 0.32%, for the testbench on the Spanish language. She further explored a mechanism of subsequent rule applications, as well as using modular components to enable better cross-lingual performance, both of which show promising results. We eagerly await these lemmatizers in the forthcoming releases of spaCy.
Go through the slides of her presentation here
ScispaCy: A full spaCy pipeline and models for scientific and biomedical text - Mark Neumann
In this talk, Mark walks us through his experience of developing ScispaCy, a fork of spaCy specific to the use-cases in biomedical NLP. The fork was sorely needed since the performance of spaCy on the biomedical domain was rather suboptimal, and existing tools, while work with reasonable accuracy, are very slow (see Fig. Below). Case in point, MetaMap{Lite} was estimated to take about a month of computation time to process 28 million paper abstracts, while ScispaCy did the job in under 24hrs.

Mark raises some important points in the talk, as he covers the numerous innovations that went into making this fork, some of which include (i) the need for domain specific solutions, (ii) utilizing domain understanding in coming up with solutions can (and did) lead to better, faster, and even more accurate systems than just relying on machine learning. His work is also an effective testament/demonstrationdemonstrateion of the extensibilityextensibilty of spaCy. From re-training components, changing their implementations, to adding new functionalities, are all possible, and as Mark put it - “not hard!”. Check out his slides for more details on ScispaCy.
Financial NLP at S&P Global - Patrick Harrison
Patrick, in his talk, gives an overview of the S&P effort to create next-gen financial dataset utilizing modern NLP techniques and active learning. Their talk focuses on creating an ESG (Environmental, Social or Governance) practices dataset of enterprises. This task is challenging because the raw data may be made available by different companies somewhere in their webpages, a public announcement, following little standard structure, but primarily because of the high quality requirements - the system’s result must be a hundred percent accurate. This is in line with S&P’s reputation - that of maintaining extensive and accurate data for a very wide variety of domains, which enables them to make critical decisions confidently. Patrick stresses the importance of collaboration between humans and machines (in an active learning setting) to maintain this requirement. He presents a pipeline approach for creating this dataset, which broadly involves data collection, sentence segmentation and subsequent classification (using spaCy textcat as a baseline, and a BERT (Devlin, Chang, Lee, & Toutanova, 2019) based model). These predictions are then passed on to domain experts who verify its correctness. Their annotations are then used to fine-tune the classifiers. This constant back-and-forth between domain experts and classification systems enables S&P to achieve broad coverage and maintain high quality in their dataset.
Here’s a link to a video recording of Patrick’s talk.
NLP in Asset Management - McKenzie Marshall
McKenzie discusses the use of NLP solutions in asset management over @ Barings (link). Well, a crucial part of asset management involves keeping on top of recent developments, trends, sentiments percolating in the wild. Sure as day, NLP solutions come in handy. She talks about one such solution which helps their analysts consume text at scale. This involves annotating documents with relevant companies and assigning sentiment scores to them.
“Augmentation, not Automation” - McKenzie Marshall
She stresses on their approach to enhance the workflows of analysts rather than replacing them. Time and again, this sentiment was expressed in numerous contexts and in our opinion, should actively drive the availability of tools and techniques in the field. Another important takeaway from her talk was her thoughts on the relationship between the data annotators and the end product. Premised on the fact that many data annotations are subjective, she states that annotators need to be integrated in the product development, needs to know its end-use very well, based on which they can make these subjective decisions in a proper (consistent) manner. She suggests that documenting the grounds on which these subjective decisions are made, and strictly adhering to them is very effective in ensuring a high quality and consistently annotated data.
Her talk, while illustrating another interesting example of applied NLP, thus walked us through some very meaningful takeaways which have a much wider appeal. Check it Out!
spaCy in the News: Quartz’s NLP pipeline - David Dodson
qz
David Dodson, in his talk, gives an overview of the NLP pipeline they have built at Quartz appropriately named $\mathsf{SiO}_{\mathsf{2}}$ (Silicon DiOxide → Quartz). He begins with an anecdote, where Quartz covered an event live, converting talks from multiple speakers available as queryable data. This laid the ideation for their current NLP pipeline. They started this effort by collecting over 70K documents and annotated each document with entities and other metadata. Then they trained their models to predict entities of the document which were then stored in a language graph (think knowledge graphs). This language graph, David says, consists of these entities, and the contexts in which they appear in the news articles. It goes unsaid that these things change, evolve over time (think the crypto news cycles from a couple of years over). Their language graph thus maintains mutability, snapshots, and diffs enabling queries like “show me everything about Elon musk in 2018”. A bird eye’s perspective of different pipelines used is as in Fig. .

$\mathsf{SiO}_{\mathsf{2}}$, apart from populating their language graph, is also used in their in-house editor, which does language style analytics on the fly; to live-analyze tweets during events (World Economic Forum, Davos). These applications, akin to the ones McKinzie talked about, are another excellent example of how NLP enabled systems are used to enhance the existing workflow, rather than replacing them. Check out his slide deck, or a video recording of his talk for a more in-depth view of this work.
Closing Comments
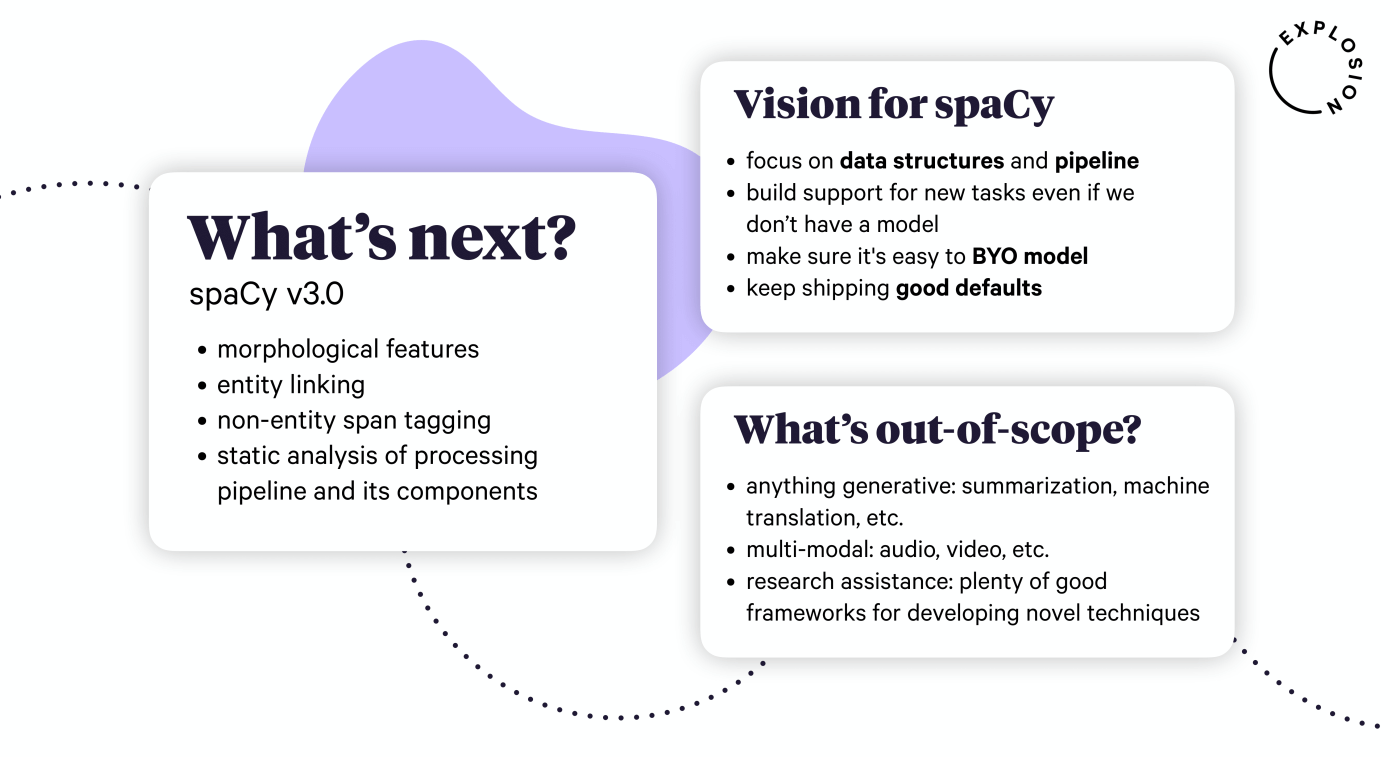
In the final talk, Matt and Ines walked us through the story of how (and why) spaCy came to be, of how it evolved and their plans with it for the future. spaCy, and Explosion.ai have some interesting plans like entity linking, on-premise spaCy ecosystem, non-entity span detection, in the future. Check out their slides, or a video recording of their talk.
Overall, the conference provided an excellent overview of the state of NLP technologies being currently used in industries, recent advances, its much needed advances. Yoav stated that NLP in industry lags far behind its recent academic developments. Patrick’s talk is a good testament of why that is the case - primarily, rigorous accuracy requirements which can’t be fulfilled by current methods. That said, interesting workflows are being developed, which provide tangible benefits with current-gen technologies, weaving around their limitations, primarily by human involvement (e.g. Fallback discussed by Justina, active learning pipelines discussed by Patrick). As McKenzie puts it, augmentation rather than automation: human machine collaboration is what is making NLP move forward in the industry.
References
- Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving language understanding by generative pre-training. URL Https://s3-Us-West-2. Amazonaws. Com/Openai-Assets/Researchcovers/Languageunsupervised/Language Understanding Paper. Pdf.
- Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) (pp. 4171–4186).
- Peters, M. E., Neumann, M., Iyyer, M., Gardner, M., Clark, C., Lee, K., & Zettlemoyer, L. (2018). Deep contextualized word representations. In Proc. of NAACL.
- Howard, J., & Ruder, S. (2018). Universal language model fine-tuning for text classification. ArXiv Preprint ArXiv:1801.06146.
- Dong, L., Yang, N., Wang, W., Wei, F., Liu, X., Wang, Y., … Hon, H.-W. (2019). Unified Language Model Pre-training for Natural Language Understanding and Generation. ArXiv Preprint ArXiv:1905.03197.
- Joshi, M., Choi, E., Levy, O., Weld, D. S., & Zettlemoyer, L. (2018). pair2vec: Compositional word-pair embeddings for cross-sentence inference. ArXiv Preprint ArXiv:1810.08854.
- Swayamdipta, S., Thomson, S., Lee, K., Zettlemoyer, L., Dyer, C., & Smith, N. A. (2018). Syntactic scaffolds for semantic structures. ArXiv Preprint ArXiv:1808.10485.
- Kiela, D., Wang, C., & Cho, K. (2018). Dynamic meta-embeddings for improved sentence representations. ArXiv Preprint ArXiv:1804.07983.
- Child, R., Gray, S., Radford, A., & Sutskever, I. (2019). Generating long sequences with sparse transformers. ArXiv Preprint ArXiv:1904.10509.
- Elazar, Y., & Goldberg, Y. (2019). Where’s My Head? Definition, Dataset and Models for Numeric Fused-Heads Identification and Resolution. ArXiv Preprint ArXiv:1905.10886.
- Ruder, S. (2019). Neural Transfer Learning for Natural Language Processing (PhD thesis). National University of Ireland, Galway.
- Maheshwari, G., Trivedi, P., Lukovnikov, D., Chakraborty, N., Fischer, A., & Lehmann, J. (2018). Learning to Rank Query Graphs for Complex Question Answering over Knowledge Graphs. ArXiv Preprint ArXiv:1811.01118.
Footnotes
-
For an excellent overview of this sub-field, we refer interested readers to Sec. 3.3 of (Ruder, 2019) ↩
-
A common workaround is to concatenate the different inputs into one sequence (e.g. Fig.1 in (Radford, Narasimhan, Salimans, & Sutskever, 2018)), or using multiple (shared) instances of the encoder corresponding to each input e.g. (Maheshwari et al., 2018). ↩