Bag of Tricks 👜 for NLP Models - (Part 1)
This is the first post in a series of simple, part-obvious, and (largely) independent hacks to increase the performance of your models slightly. Anything you find here, you should be able to pick-n-choose, which might give you that slight edge.
This series is primarily based on a presentation I gave in my lab earlier this year. You can just go over the presentation if you’d rather have that.
0. Why?
-
- Add more information
- A bunch of stuff here focuses on adding information to the inputs, which the model might learn to include in solving the task (think: positional embeddings in Seq2Seq; capitalization during entity linking etc)
-
- De-incentivize/incentivize the use of information, actively
- Regularization. I mean regularization.
-
- Mutually Assured Armament
- Say you’re testing a hypothesis, hoping that your model outperforms the others on a given task. Chances are, the other model was trained with a bunch of these tricks1 (stated in their work, or not), giving it the edge over your otherwise valid hypothesis.
<rant>And while these tricks might not have anything to do with your hypothesis/contributions, you’re going to need to put them in, complicate your codebase, and find optimum hyper-parameters when trying to outperform the others.</rant>
This is not necessarily a bad thing, especially when you’re making a tool or a system/model designed for reusability/in-production. More on this sometime later.
1. Pre-processing
To begin with, let’s go over something very fundamental - “preprocessing the text before throwing it in the model.”
1.1. Tokenization
The first step, in most word-based models, is to break up sentences/sequences into words or tokens. In the simplest setting, you’d just split the sequence with space.
"you'd just split the sequence with space" ->
["you'd", "just", "split", "the", "sequence", "with", "space"]
Notice the first word there? There are countless such edge-cases that would have to be worked in for a decent tokenization mechanism. Consider -
I.M.O. the never-to-be-forgotten acting of Robert Downey Jr. reached its zenith with Sherlock Holmes: A Game of Shadows, which premiered on 16th-Dec. in the US as well as worldwide
Could you imagine covering all these edge cases meticulously in your code? Should you forgo this nuance for the sake of dev time? I would just use an NLP library. spaCy is an excellent choice. So is AllenNLP, or FastAI. But anything is better than ignoring these edge cases or covering them manually.
Here’s a small example, using spaCy [src]:
from spacy.tokenizer import Tokenizer
from spacy.lang.en import English as Lang # Can use mutliple languages
nlp = Lang()
tokenizer = Tokenizer(nlp.vocab)
for doc in tokenizer.pipe(dataiter, batch_size=10000, n_threads=5):
for tok in doc:
...
BTW here’s a brilliant blog post on tokenization over at IBM Community Blogs
1.2. Meta-data
Or throwing more information to your model than simple lowercased word IDs.
1.2.1. Capitalization

There are three ways to go about it.
-
- Lowercase everything.
- This works for a wide variety of approaches. But now, more than ever, capitalization has a semantic connotation: shouting, abbreviations, sNiDe etc . Do you need this information for solving all NLP tasks? Of course not. Do you need it for many NLP tasks? Maybe. Why not let the model decide?
-
- Leave as is.
- So then, you could leave the text as is. However, you’d end up increasing your vocabulary size (See Managing Vocabulary). Worse, for word/word-phrase level models 2, there would be no correlation between
potato,Potato, andPOTATO. At best, you could initialize them all with the same word vectors, which overtime will diverge from each other. The model would also be completely flabbergasted byuTTerAncEs lIkE thIs3.
-
- Explicitly note capitalizations
- A reasonable tradeoff between including the information, and not blowing up the vocabulary space is to use tags to denote these capitalizations. Any model worth its salt should be able to infer that the next word is capitalized upon noticing a
<cap>tag. I would use a combination of<cap>and<allcap>forPotatoandPOTATOrespectively (See Fig. 1).
1.2.2. Start, end tags
Many language models are trained with <start> and <end> tag to denote, well, the start and end of sequences, obviously. If you’re using a pre-trained model, do not forget to append them to your inputs. Who am I kidding? You probably won’t. I did. And it took me more than a week to figure out that this was the problem. And I promised myself I’ll own up to this mistake publicly and so here we are. Peace.
PS: You could also throw these tags in even if you’re not using a pre-trained model. Might help.
1.3. Managing Vocabulary
For generic tasks (which do not include entity linking, entity recognition, or pretty much anything to do with proper nouns), you probably don’t need a 6 digit vocabulary size. Why not try capping it to something smaller?
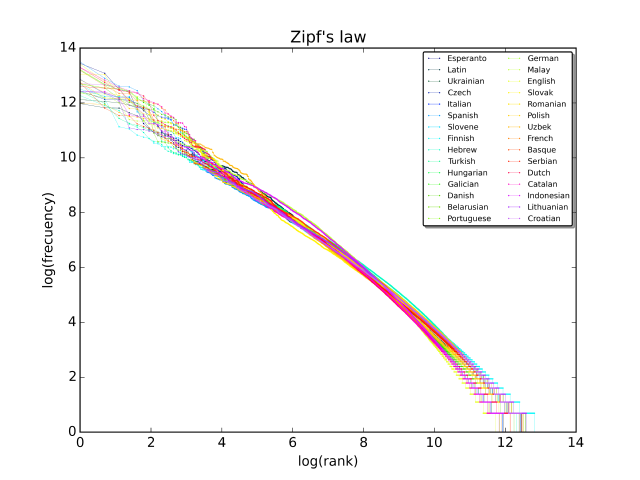
If Zipf’s law is anything to go by, word frequency drops exponentially as its rank increases. That is to say, with a large vocabulary, the datasets infrequent words can get really infrequent.
Consider the word supercalifragilisticexpialidocious4. Unless your model is trained over the transcript of Mary Poppins, the model probably encounters it less than a dozen times. Consequentially, the embeddings for this word are as good as untrained. But worse than that of __unk__ or the unknown token. You might have been better off not including this word (despite its myriad advantages) in our vocabulary in the first place.
So then, how do you decrease your vocabulary? A good approach would be to decrease it based on word occurrence frequency. You could constrain your vocab to only include words that appear more than 10 times. Better, you could constrain it to include the 60,000 most frequent words. This can really come in handy when you’re working with little training data, btw.
PSA: Remember to only comb through the trian and validation splits (exclude the test split) while making the vocabulary, regardless of pruning strategies. Thank you.
2. Sampling
Sampling, or throwing the pre-processed data and throwing it to the model while training.
Context: We focus on recurrent (although, not necessarily) models, working with language data.
2.1. Sortish Sampling
tl;dr: sort the dataset based on sequence lengths, and gather inputs of similar sequences in each batch. You could end up minimizing the __pad__ tokens, significantly.
Pad tokens (__pad__) tokens are used to ensure that different sequences in a batch of sampled data are of the same length. This can be problematic since the summary vector (last hidden state vector) end up encoding one or many of these __pad__ tokens, along with the actual text.
A simple technique to significantly reduce the number of these pad sequences then is to sort the dataset based on sequence length, and sequentially (not randomly) sample from it. This way, a batch will be composed of sequences of similar lengths, and consequentially we’ll end up using significantly less __pad__ tokens to equate their lengths.


E.g. Randomly sampling from English sentences in WMT 2014 EN-DE with batch size bs=64, we get an average of 43.7 pad tokens per sequence. With sortish sampling, the number’s changed to 0.0012.
PS: Other way to deal with __pad__ tokens is to use better implementations of RNNs (wait for Part 2 of this post).
2.2. Variable Length Backpropagation Through Time
tl;dr: when training a language model, chunk sequences of random length.
Consider the following as a representation of a text document of (13*10=) 130 words. While training a language model, we chunk it based on a sequence length seqlen (number of words), say 10. That’s 13 chunks/samples, none of which would change across epochs.
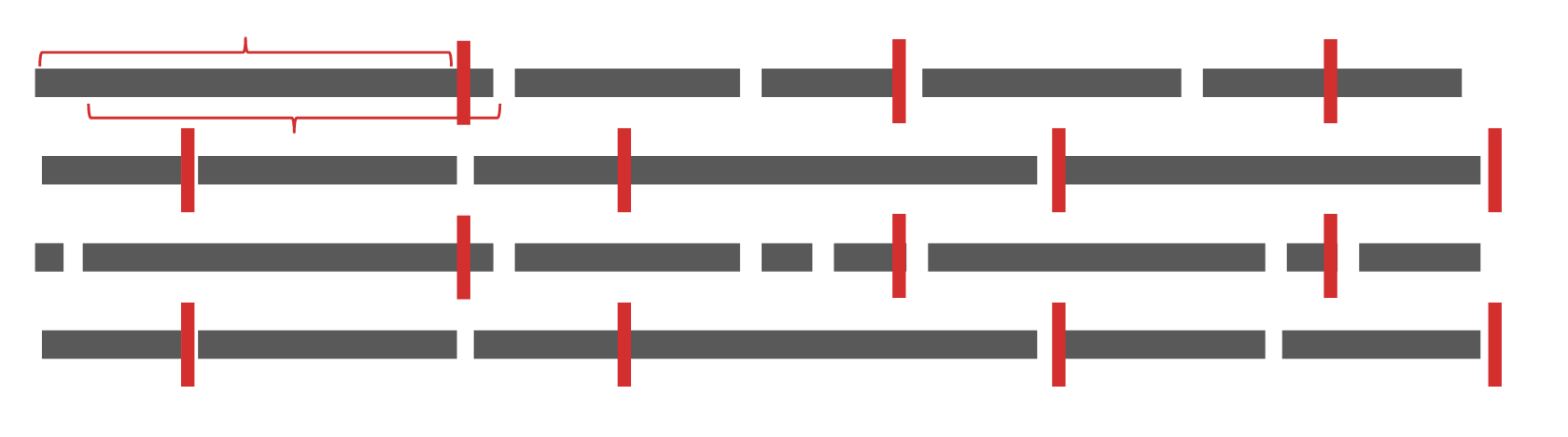
Now for each chunk, consider the backward pass (Figure below). The backpropagation through time (BPTT) algorithm has a window of i mod seqlen . That is to say that while backpropagating through the 5th word ($w_4$) in the sequence, the gradients accumulate errors made in predicting the 1st, 2nd, …, 5th outputs ($\vec{o}_0 \ldots \vec{o}_4$). For the 2nd word, $w_1$, it’ll take into account the errors made in predicting the 1st output ($\vec{o}_0$). However for the first word ($w_0$), there’d be no such prediction. Thus, the time window for the first word, eleventh word and so on is 0 (i mod seqlen). Effectively, $\frac{1}{10}^{th}$ or $\frac{1}{seqlen}^{th}$ of the dataset is not being used to improve the model. And remember, since the chunks are constant across epochs, these words will never be used.

Thus, instead of fixing seqlen to be a constant, we randomly vary it. E.g. we can sample the seqlen from a gaussian centred at 10, with σ as a hyperparameter. This way, each chunk will be different, and after some epochs we’d have seen all of the dataset in different BPTT windows.
Just remember to scale the learning rate corresponding to the sampled sequence length. To the best of my knowledge, this technique was first proposed in (Merity, Keskar, & Socher, 2017).
Implementations and Closing Comments
In this first part of the post, we went over some tweaks to a typical5 pre-processing and sampling parts of training neural networks. Following is both a summary, and some implementations that you can use/copy to yours.
For many of these and other related things, I maintain MyTorch (is your torch 🔥🔥🔥). A boilerplate for PyTorch code, which I’ve tried to keep modular (you can pick-n-choose some aspects); flat; and very transparent.
-
- tokenization
!= text.split(' '). Use a library! - implementation: spaCy, MyTorch > nlutils > preproc (A wrapper over spaCy), AllenNLP, FastAI, NLTK.
- tokenization
-
- using
<cap>,<allcap>tags to denote capitalized words in the input. - implementation: DIY
- using
-
- Vocabulary pruning. Keep most frequent
nwords as the model’s vocabulary. - implementation: MyTorch > utils > goodies > Counter.
- Vocabulary pruning. Keep most frequent
-
- For recurrent models, it might be better to sort the dataset w.r.t. sequence lengths, and then sample from it.
- implementation: MyTorch > dataiters > SortishSampler, fastai.
-
- For recurrent language models, vary the chunks of text you train with.
- implementation: fastai.
In the next post, we’ll go over changes to (i) neural architectures and (ii) optimisation schemes that might positively affect your model’s performance.
References
- Merity, S., Keskar, N. S., & Socher, R. (2017). Regularizing and optimizing LSTM language models. ArXiv Preprint ArXiv:1708.02182.
Footnotes
-
optimizations, hacks, tricks, tweaks, and whatnots. ↩
-
Those where the input is a sequence of words -
['potatoes', 'are', 'fun']. In contrast with character level models where the input is a sequence of characters -['p', 'o', 't' ....]↩ -
Even though the sound of it is something quite atrocious.
If you sing it loud enough you’ll always sound precocious.
supercalifragilisticexpialidocious. ↩ -
Your mileage may vary. ↩